BERT (Representaciones de codificador bidireccional de transformadores) es un modelo de procesamiento de lenguaje natural propuesto por investigadores de Google Research en 2018. Cuando se propuso, logró una precisión de vanguardia en muchas tareas de NLP y NLU, como:
- Evaluación general de comprensión del lenguaje
- Conjunto de datos Q/A de Stanford SQuAD v1.1 y v2.0
- Situación con generaciones antagónicas
Poco después del lanzamiento, se publicó el código de fuente abierta con dos versiones del modelo preentrenado BERT BASE y BERT LARGE que se entrenan en un conjunto de datos masivo. BERT también utiliza muchos algoritmos y arquitecturas de NLP anteriores, como el entrenamiento semisupervisado, los transformadores OpenAI, ELMo Embeddings, ULMFit, Transformers. Arquitectura modelo BERT: BERT se lanza en dos tamaños BERT BASE y BERT LARGE . El modelo BASE se utiliza para medir el rendimiento de la arquitectura en comparación con otra arquitectura y el modelo LARGE produce resultados de última generación que se informaron en el trabajo de investigación. Aprendizaje semisupervisado:Una de las principales razones del buen desempeño de BERT en diferentes tareas de PNL fue el uso del aprendizaje semisupervisado . Esto significa que el modelo está capacitado para una tarea específica que le permite comprender los patrones del idioma. Después de entrenar, el modelo (BERT) tiene capacidades de procesamiento del lenguaje que se pueden usar para potenciar otros modelos que construimos y entrenamos usando el aprendizaje supervisado.

Aprendizaje semisupervisado
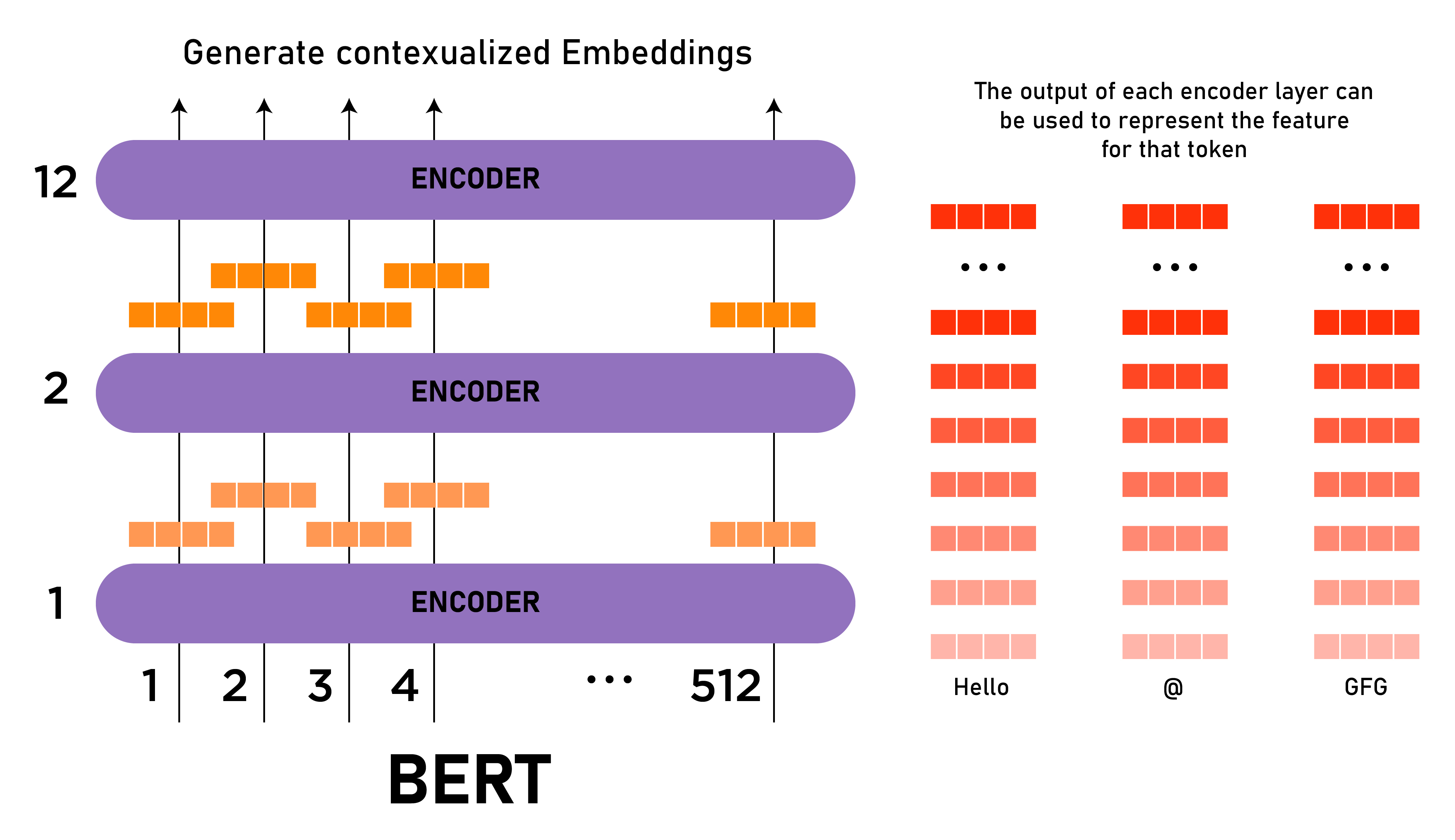
BERT es básicamente una pila de codificadores de arquitectura de transformadores. Una arquitectura de transformador es una red de codificador-decodificador que utiliza la autoatención en el lado del codificador y la atención en el lado del decodificador. BERT BASE tiene 1 2 capas en la pila del codificador mientras que BERT LARGE tiene 24 capas en la pila del codificador . Estos son más que la arquitectura Transformer descrita en el artículo original ( 6 capas de codificador ). Las arquitecturas BERT (BASE y LARGE) también tienen redes de retroalimentación más grandes (768 y 1024 unidades ocultas respectivamente) y más cabezas de atención (12 y 16 respectivamente) que la arquitectura Transformer sugerida en el documento original. Contiene512 unidades ocultas y 8 cabezas de atención . BERT BASE contiene 110M de parámetros mientras que BERT LARGE tiene 340M de parámetros.
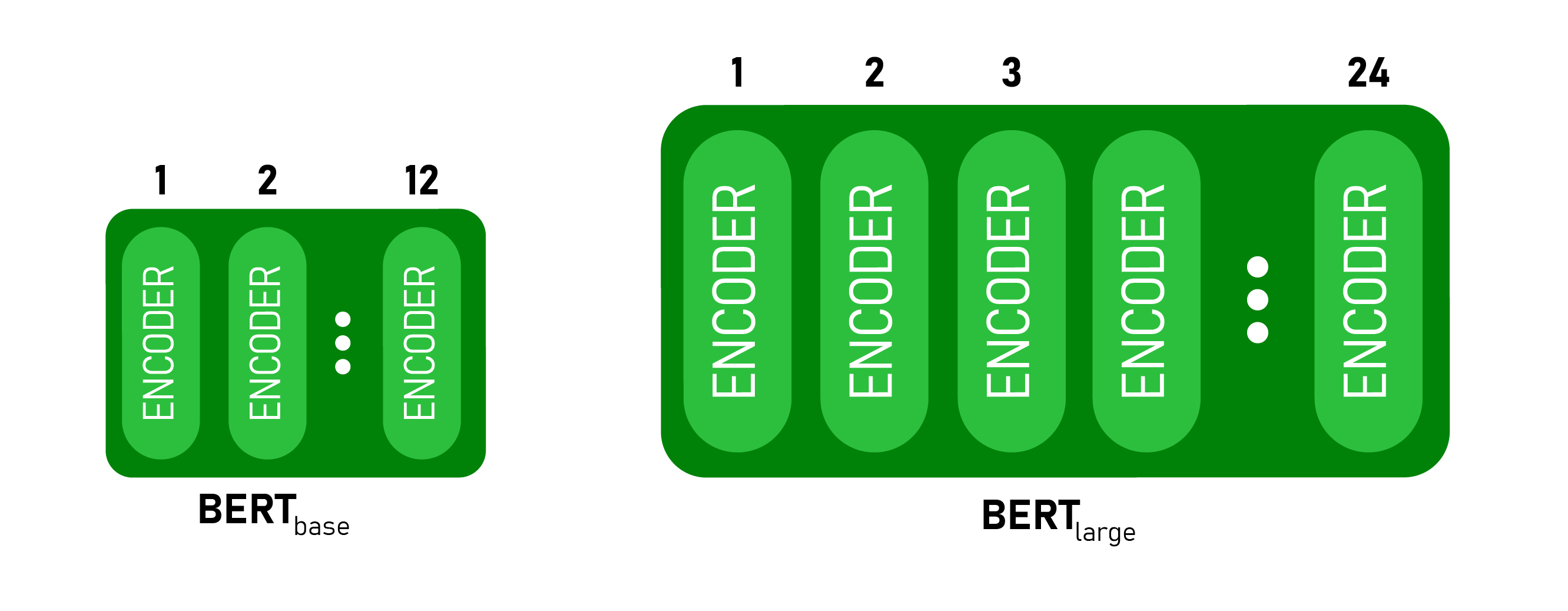
Arquitectura BERT BASE y BERT LARGE .
Este modelo toma el token CLS como entrada primero, luego le sigue una secuencia de palabras como entrada. Aquí CLS es un token de clasificación. Luego pasa la entrada a las capas anteriores. Cada capa aplica la autoatención, pasa el resultado a través de una red de avance y luego pasa al siguiente codificador. El modelo genera un vector de tamaño oculto ( 768 para BERT BASE). Si queremos generar un clasificador de este modelo, podemos tomar la salida correspondiente al token CLS.
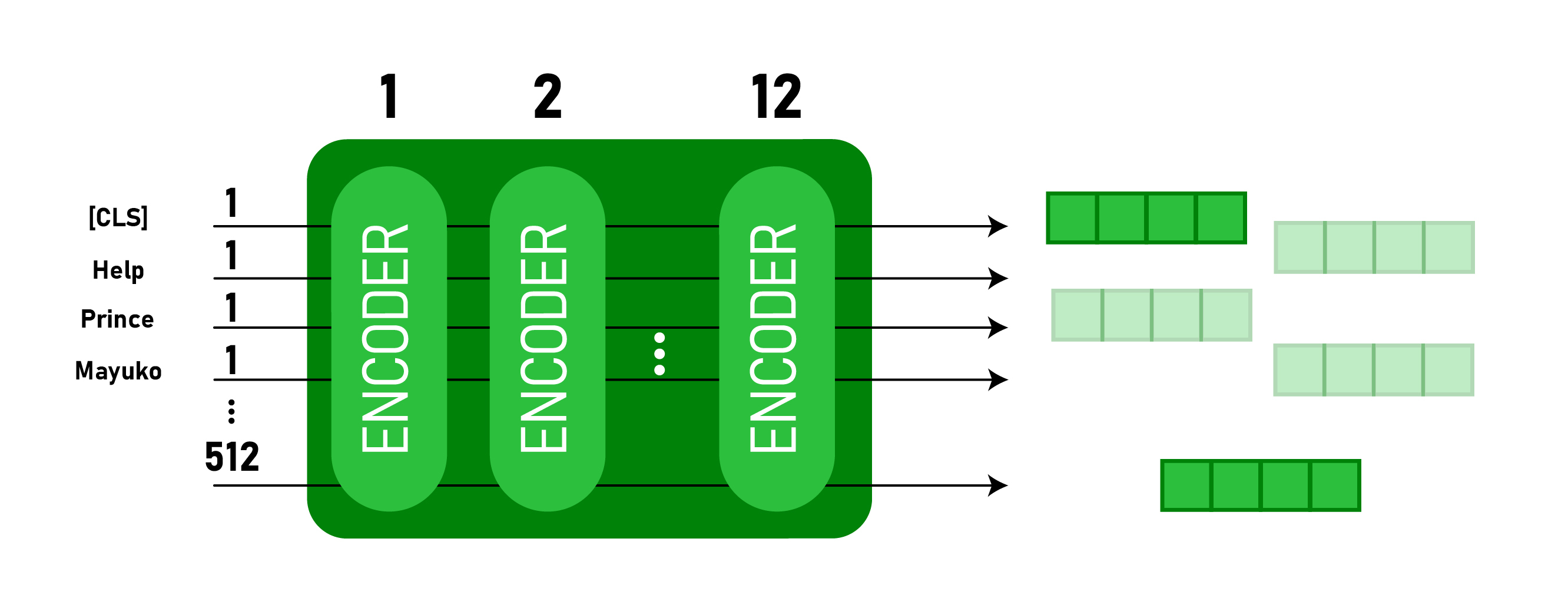
Salida BERT como incrustaciones
Ahora, este vector entrenado se puede usar para realizar una serie de tareas, como clasificación, traducción, etc. Por ejemplo, el documento logra excelentes resultados simplemente usando una sola capa NN en el modelo BERT en la tarea de clasificación. ELMo Word Embeddings: este artículo es bueno para recapitular Word Embedding. También analiza Word2Vec y su implementación. Básicamente, incrustaciones de palabras para una palabra es la proyección de una palabra a un vector de valores numéricos basados en su significado. Hay muchas palabras incrustadas populares como Word2vec, GloVe, etc. ELMo era diferente de estas incrustaciones porque le da incrustaciones a una palabra en función de su contexto, es decir, incrustaciones de palabras contextualizadas. Para generar la incrustación de una palabra, ELMo mira la oración completa en lugar de una incrustación fija para una palabra. Elmo usa un LSTM bidireccional capacitado para la tarea específica para poder crear esas incrustaciones. Este modelo se entrena en un conjunto de datos masivo en el lenguaje de nuestro conjunto de datos, y luego podemos usarlo como componente en otras arquitecturas que se requieren para realizar tareas de lenguaje específicas.
Elmo Contextualizar Embeddings Arquitectura
ELMo obtuvo su comprensión del lenguaje al ser entrenado para predecir la siguiente palabra en una secuencia de palabras, una tarea llamada Modelado del lenguaje. Esto es conveniente porque tenemos una gran cantidad de datos de texto de los que un modelo de este tipo puede aprender sin que se puedan entrenar etiquetas. ULM-Fit: Transferencia de aprendizaje en PNL: ULM-Fit presenta un nuevo modelo y proceso de lenguaje para ajustar de manera efectiva ese modelo de lenguaje para la tarea específica. Esto permite que la arquitectura NLP realice transferencias de aprendizaje en un modelo preentrenado similar al que se realiza en muchas tareas de visión artificial. Open AI Transformer: Entrenamiento previo:La arquitectura del transformador anterior solo tiene la arquitectura del codificador entrenada previamente. Este tipo de entrenamiento previo es bueno para una determinada tarea, como la traducción automática, etc., pero para tareas como la clasificación de oraciones, la predicción de la siguiente palabra, este enfoque no funcionará. En esta arquitectura, solo entrenamos decodificador. Este enfoque de entrenamiento de decodificadores funcionará mejor para la tarea de predicción de la siguiente palabra porque enmascara tokens futuros (palabras) que son similares a esta tarea. El modelo tiene 12 pilas de las capas del decodificador. Como no hay codificador, estas capas de decodificador solo tienen capas de autoatención. Podemos entrenar este modelo para la tarea de modelado de lenguaje (predicción de la siguiente palabra) al proporcionarle una gran cantidad de conjuntos de datos sin etiquetar, como una colección de libros, etc.
Predicción de la siguiente palabra de transformadores OpenAI
Ahora que el transformador Open AI tiene cierta comprensión del lenguaje, se puede usar para realizar tareas posteriores como la clasificación de oraciones. A continuación se muestra una arquitectura para clasificar una oración como «Spam» o «No Spam».

Transformadores de OpenAI Tarea de clasificación de oraciones
Resultados: BERT proporciona resultados ajustados para 11 tareas de NLP. Aquí, discutimos algunos de esos resultados en tareas de PNL de referencia.
- PEGAMENTO: La tarea de evaluación de la comprensión del lenguaje general es una colección de diferentes tareas de comprensión del lenguaje natural. Estos incluyen MNLI (Inferencia de lenguaje natural multigénero), QQP (Pares de preguntas de Quora), QNLI (Inferencia de lenguaje natural de preguntas), SST-2 (El banco de sentimientos de Stanford), CoLA (Corpus de aceptabilidad lingüística), etc. Ambos, BERT BASE y BERT LARGE supera a los modelos anteriores por un buen margen (4,5% y 7% respectivamente). A continuación se muestran los resultados de BERT BASE y BERT LARGE en comparación con otros modelos:
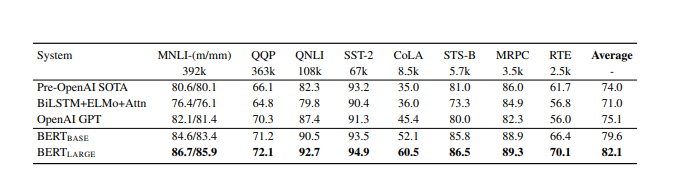
Resultado de BERT en la tarea GLUE NLP
- SQuAD v1.1 Conjunto de datos de preguntas y respuestas de Stanford El conjunto de datos es una colección de 100 000 pares de preguntas y respuestas de fuentes multitudinarias. Un punto de datos contiene una pregunta y un pasaje de wikipedia que contiene la respuesta. La tarea es predecir el intervalo de texto de respuesta del pasaje. El BERT con mejor desempeño (con el conjunto y TriviaQA) supera al sistema de clasificación superior por 1.5 puntaje F1 en conjunto y 1.3 puntaje F1 como un solo sistema. De hecho, BERT BASE individual supera al mejor sistema de conjunto en términos de puntuación F1.
- SWAG (Situaciones con generaciones antagónicas) El conjunto de datos SWAG contiene 113.000 tareas para completar oraciones que evalúan la respuesta más adecuada mediante una inferencia de sentido común fundamentada. Dada una oración, la tarea es elegir la continuación más plausible entre cuatro opciones. BERT LARGE supera a OpenAI GPT en un 8,3 %. Incluso funciona mejor que un humano experto. El resultado del conjunto de datos SWAG se muestra a continuación:

Resultados en el conjunto de datos SWAG
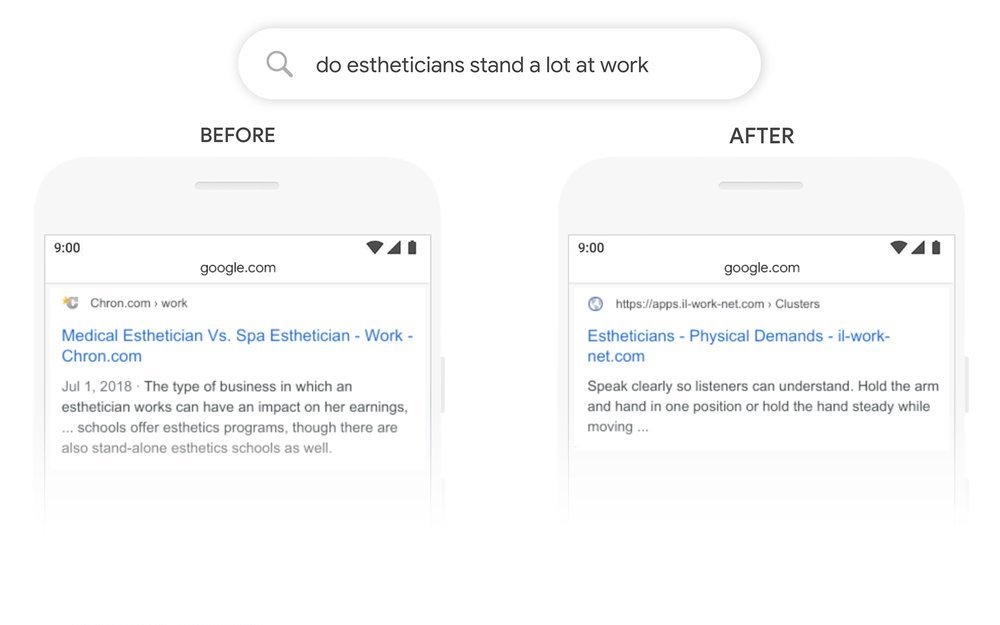
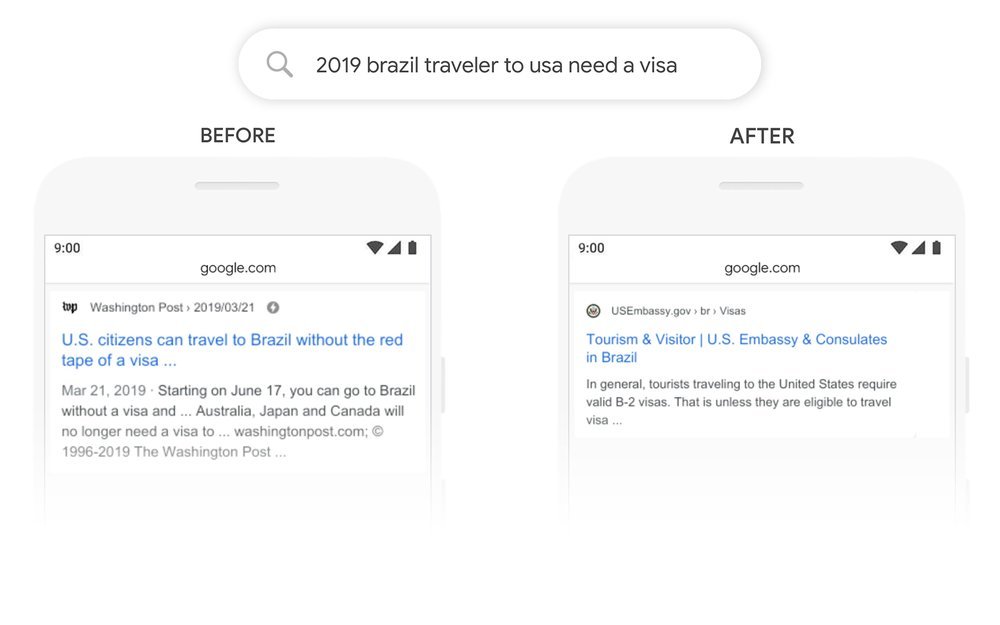
Conclusión: BERT pudo mejorar la precisión (o puntaje F1) en muchas tareas de procesamiento de lenguaje natural y modelado de lenguaje. El principal avance que proporciona este documento es permitir el uso del aprendizaje semisupervisado para muchas tareas de PNL que permiten transferir el aprendizaje en PNL. También se usa en la búsqueda de Google, a partir de diciembre de 2019 se usó en 70 idiomas. A continuación se muestran algunos ejemplos de consultas de búsqueda en Google antes y después de usar BERT. Referencias: